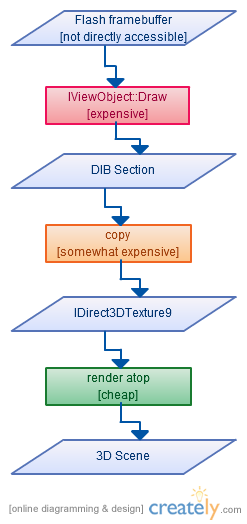
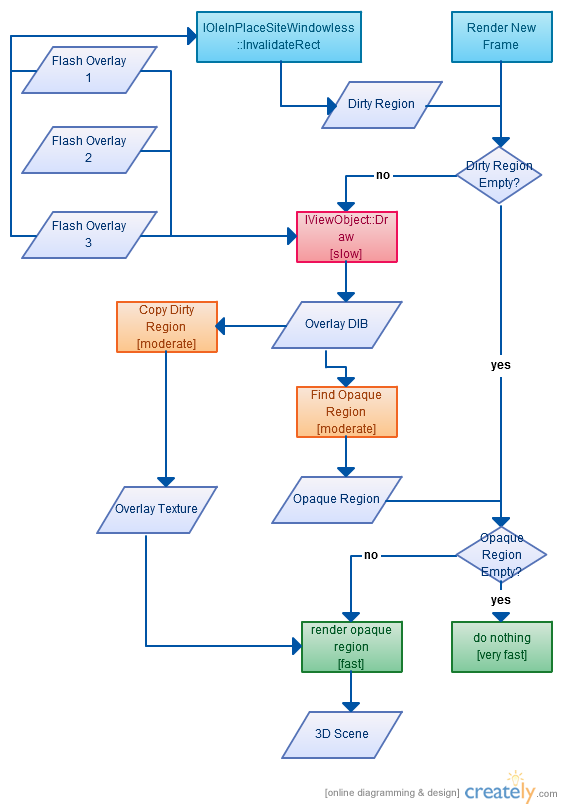
IMVU partners with several companies to provide extra services on our website that are not our core competencies, especially when it makes more sense to use others that already implement the service. Each of these integration efforts is a new process, but we have found several practices that make them easier to accomplish and more likely to succeed.
Doing a technical review during the initial partner evaluation sounds obvious, but is extremely critical. Not just at the marketing level, but having our engineers talk with theirs about the expectations we have on performance (connections per second, etc.) as well as the actual integration work helps reduce confusion before the effort starts. Several times we have surprised our partners with either the usage we expect for a new feature, or how we want to integrate their services into our entire development cycle. Sometimes the technical review at this stage determines that it won’t really be reasonable to do the integration – helping us to ‘fail fast’ instead of waiting until attempting the integration.
Continuing this communication on through the initial implementation effort is also important. The best way to accomplish this is having both sets of engineers co-located during the initial integration effort. We have found that having the engineers from our partner work directly with our engineers helps cut down on the communication delays. There are always questions during any integration, about API documentation or error messages or just adding logging to determine why a given request isn’t working – having engineers in the same room helps immensely. The timing on this is also critical – we do not want to have someone fly out before we’ve started the integration work, but we also do not want to go too far down the rabbit hole before having an expert there to help. Having flexible partners helps – during one integration process we ran into difficultly far earlier than expected – our east-coast partner flew out an engineer the next day to work with our team, and he stayed until we determined the problem.
Another part is being able to integrate tests against our external partners into our continuous integration process. We have several solutions here – first, we implement a full ‘fake’ version of the partner’s API that we use during standard commits. This allows our large suite of unit and functionality tests to not be dependent on external connections that would make them slower and sometimes intermittent. We also have a separate set of tests that we run against the actual API. These include tests that confirm our fake APIs work the same as the actual APIs. These external tests are run every couple of hours, so we can detect if the partner’s APIs change. The combination of these tests allow us to feel confident with our continuous integration efforts, even when doing things like changing our Music Store (which talks to our music partner).
Metrics and graphing are also a very important part of our process. They let us quickly determine if there is a problem with the connection to our partner. The faster you know there is a problem, the faster you can respond! (A couple of times during my first years at IMVU, we only found out about problems through our forums – not the way to respond quickly to problems! Plus, it becomes far harder to fix the problem when you don’t know exactly when it started…) For these integrations, we keep several levels of metrics. First, each point where we talk to an external customer gets metrics – for example, each music purchase attempt gets counted from our side. But we also ask our partners to expose a service to report their own metrics to us. This gives us better pointers to problems when they do occur – i.e. if there is a problem with the network connections between our servers and our partners’ servers.
The metrics and graphing are only a part of the continuing maintenance that we put in place. Another major part is communication paths. We create an internal mailing list that we ask our partners to send all email to – so when we internally change responsible individuals we don’t have to have all of our partners change their address books. We also ask our partners to let us know as soon as possible whenever they detect a problem, then follow up later on to let us know how they solved the problem. Where available, we’ve asked our partners to include our contact info for some of their monitoring alerts. Our operations staff also has contact details and a call escalation path for our partner and solution instructions so they know how to handle any alerts that are triggered by our monitoring.
So, in review – for partners of IMVU, here is the checklist we (currently) follow:
* Initial engineering technical review before any contract is signed
* Co-located engineering support early in the integration schedule (usually within the first week or two)
* Regular testing calls being made to the partner’s APIs (including test purchases, etc.)
* Expose a web service containing real-time metrics important for the integration
* Call escalation path for operations if issues arise
* Continuous communication about scheduled maintenance, unplanned issues, or upcoming upgrades.