In this 3-part series, IMVU senior engineer Bill Welden describes the means and technology behind IMVU’s web services.
Part 3: Documents and Links
In the previous entry in this series I described how IMVU uses a structured network model to implement the uniform contract for our REST services and showed how they might apply to a set of services for a hypothetical high school scheduling system.

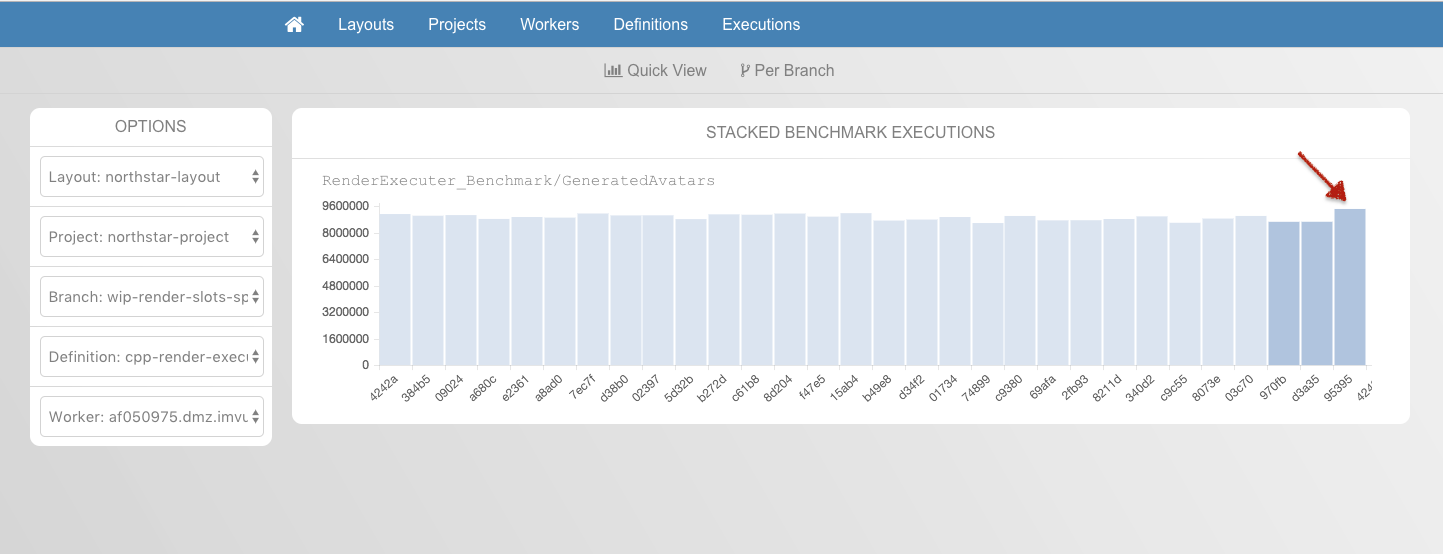
Under this model we have Node Groups (represented by the different colors of circles in this diagram), Nodes (the circles themselves), Edge Groups (the rounded boxes hanging off of the circles) and Edges (the lines connecting the circles).
We model these various notions using HTTP documents linked together with URLs. There are four kinds of documents, corresponding to each of the four concepts.
A Node Group determines the properties and relationships of the Nodes, and the corresponding Node Group Document contains a list of URLs, each locating a Node.
A Node, through its properties and relationships, is the basic repository of information in the network. The Node Group Document contains the values of the Node’s properties, as well as a list of URLs, each locating an Edge Group.
An Edge Group groups together all of the links that go to a particular type of Node. The corresponding Edge Group Document, specific to a Node, contains a list of URLs, each locating an Edge within that group.
An Edge is a link from its Node to another Node, usually of a different class. Edges can also contain properties, as we saw last time. An Edge Document therefore contains a URL for the Node at the other end of the Edge, as well as the values of any properties of the Edge.
Each type of document has a distinctive URL.
The URL for a Node Group Document consists of a single path segment, a singular noun describing the Node Group:
https://api.imvu.com/course
The URL for a Node consists of two path segments: the Node Group URL extended by a segment consisting of a unique identifier for the Node. The Node identifier can be any string, but we encourage the use of Node Identifiers which contain the name of the Node Group:
https://api.imvu.com/course/course-1035
The URL for an Edge Group consists of three segments: the Node URL extended either by a plural noun naming the Node Group that the Edge Group points off to, or by a noun describing the relationship created by the Edge Group:
https://api.imvu.com/course/course-1035/teachers
https://api.imvu.com/course/course-1035/roster
The URL for an Edge consists of four segments: the Edge Group URL extended by an identifier for the Edge. This identifier need only be unique within the Edge Group. Sometimes (for convenience) it is identical to the unique identifier of the Node that the Edge points to, but this is not required:
https://api.imvu.com/course/course-1035/teachers/1
https://api.imvu.com/course/course-1035/roster/student-5331
These URL formats are a constraint on the service design – a strong suggestion but not a strict requirement.
Note especially that, according to the principle of HATEOAS (Hypertext As The Engine Of Application State), the client cannot depend on any specific format, and is not allowed to construct these URLs or attempt to extract information from them. All URLs required by the client must be obtained whole, as opaque strings, from the response to an earlier service request.
Specifically, URLs returned from the server must be fully qualified, including the protocol and server name (“https://api.imvu.com”). However, in our own internal discussions and here in this presentation, we will often leave off the protocol and server name for clarity. So:
/course
/course/course-1035
/course-1035/teachers
and so forth. Wherever one of these relative URLs appears in the discussion below, the actual implementation will return a fully qualified version.
One of the biggest differences between REST services and the earlier Remote Procedure Call style is that RPC APIs define as many verbs as required by or convenient for implementation of the application. Designing RPC services is primarily about designing new verbs and specifying their parameters and their semantics.
With IMVU Rest services, the verbs are specified, and there are only five of them. Designing a service consists of designing a set of Nodes and Edges, together with their properties and relationships, in such a way that these five verbs can provide all of the required functionality.
The verbs are
GET (any endpoint)
POST (to a Node or Edge),
POST (to a Node Group or an Edge Group),
POST (to a Node Group, including Edges), and
DELETE (a Node or Edge)
GET retrieves the document associated with the URL, which can be a Node Group Document, Node Document, Edge Group Document or an Edge Document. GETs must be nullipotent, which is to say that they can have no side-effects.
POST, when applied to a Node or Edge URL makes changes to the properties and relations of the Node or Edge. Such POSTs must be idempotent, which means that sending to POST twice must have exactly the same effect as sending it once.
When POST is applied to a Node Group or Edge Group, it adds a new Node or a new Edge. Such POSTs will not be idempotent, since sending the POST twice will add two new Nodes or two new Edges.
There is a third sort of POST, a POST specifically to a Node Group which adds a new Node, but which also contains data for a set of new Edges to be added along with the Node (including Edge Groups as necessary).
Finally there is DELETE, which is used to delete a Node or an Edge. The implementation of DELETE must be idempotent.
GET returns the document associated with the URL, but in order to minimize round trips the service is allowed to return any additional documents that it thinks the client may soon need.
You can see this in the format of the JSON document returned by a GET:
{
"id": "/course/course-1035",
"status": "success",
"denormalized":
{
"/course/course-1035": { … }
"/course/course-1035/teachers": { … }
"/course/course-1035/teachers/1": { … }
… etc …
}
}
There is a status, “success” or “failure”, and if the GET fails, some information about why, but if it succeeds a package of endpoints is included, grouped under the response member “denormalized”.
In this example the client has asked for a Course, and the server has chosen to return not only the Course Node, but the Edge Group and Edges for all of the teachers that teach that course.
Each of the four kinds of documents in these responses has a specific JSON format.
A Node Group Document has a member “nodes” which is an array of URLs, one for each Node.
{
"nodes": [
"/course/course-1035",
"/course/coures-1907",
...
]
}
If the client wants to present the list of Nodes in a certain order, it is responsible for sorting them itself. It cannot depend on the order of entries in this array.
A Node Document has two members. The “data” member contains the Node’s properties. The “relations” member contains the URLs that link the Node to its Edge Groups and to other Nodes in the system.
{
"data": {
"description": "Algebra I",
"starting_time": "10:00"
}
"relations": {
"teacher": "/teacher/teacher-372",
"roster": "/course/course-1035/roster"
}
}
Names in these objects represent a contract with the client. Based on the name, the server guarantees the semantics of the value including its type, the allowed values, the meaning of the value and if it is a link, the Node Group of the Node it points to.
Note that here “teacher” is a link to a Teacher Node. This design precludes the possibility of team teaching where there are two teachers for a class.
Links directly from one Node to another create a one-to-N relationships. One Teacher to many Courses. As a rule, however, relationships are more often N-to-N than not, and such restrictions on cardinality are a red flag. Not wrong, necessarily, but something that may be called out in design reviews.
The design could be made to support many teachers per course by implementing an Edge Group “teachers” for Course Nodes. This is a more flexible design, because the cardinality restrictions, say a maximum of two teachers, or allowing multiple teachers only for certain courses, can be implemented on the server, where they are easier to change.
An Edge Group Document has a member “edges” which is a JSON array of URLs for the Node’s Edges.
{
"edges": [
"/course/course-1035/roster/student-5331",
"/course/course-1035/roster/student-1070",
...
],
}
Again, the client cannot depend on the order that the Edges come back from the server.
Finally, an Edge Document has an optional “data” member for when the Edge has properties, and a “relations” member which contains the URL for the Node at the other end of the Edge.
{
"data": {
"tardies": 1,
},
"relations": {
"ref": "/student/student-5331"
}
}
Here is an Edge between one Course (course-1035) and one Student (student-513312).
Edges go both ways. Here are the Edges between that same student and his courses.
{
"edges": [
"/student/student-53312/schedule/01",
"/student/student-53312/schedule/02",
...
],
}
Now it’s not required to implement every Edge Group implied by the Node/Edge model, so it’s acceptable to implement only half of this Edge relationship without its symmetrical partner. When we have an Edge Group in our design, however, we think carefully about the symmetrical Edge Group. It’s often a very interesting view on the data, and it’s seldom very difficult to implement.
Note that the Edge document itself can come back in two different ways, but the underlying database record will be the same. Here is one of the Edge documents linked from the Edge Group above:
{
"data": {
"tardies": 1,
},
"relations": {
"ref": "/course/course-1035",
}
}
Whether you look at this link from the Student or the Course perspective, the count of tardies is the same data element.
Nodes and Edges are updated using the same JSON document format as the response from a GET, though there is no denormalization envelope.
Here is the document for a POST to a Student Node (/student/student-513312) intended to update the student’s birth date and counsellor (documents for POSTs to Edges look pretty much the same):
{
"data": {
"birth_date": "5/11/96",
},
"relations": {
"counsellor": "/teacher/teacher-121"
}
}
If a property is missing from the data or relations sections, it is left unchanged in the Node or Edge.
The response which comes back from a POST to a Node or Edge is the same as the response from a GET to that Node or Edge, including additional denormalized data at the discretion of the server.
New Nodes and Edges are added by posting to the corresponding Node Group or Edge Group and providing the data and relations for the new Node or Edge in the body of the POST. This is a document POSTed to /course/course-1035/roster to create a new Edge, enrolling a new student in a course:
{
"relations": {
"ref": "/student/student-10706"
}
}
All of the required properties must be included in this kind of POST. A POST creating a new Node looks pretty much the same.
Again, the response to this kind of POST is the same as you would receive from a GET to the newly created Node or Edge (though you will only know the id of the new Node or Edge once the response comes back).
It is often useful to be able to add a Node and a number of Edges in one POST request. The response would include the new Node, a new Edge Group and all of the specified Edges. Here is a POST to /student which adds a new Student along with Enrollment Edges in two courses:
{
"data": {
"name": "Andrew",
"birth_date": "7/21/95"
},
"edges": {
"schedule": [
{
"relations": {
"ref": "/course/course-1035"
}
},
{
"relations": {
"ref": "/course/course-2995"
}
},
]
}
}
The only other verb is DELETE, which can be applied to a Node or an Edge by providing the URL of the Node or Edge. No document is passed with a DELETE request. DELETEing a Node will also delete all of the Edge Groups and Edges for that Node.
The service implements much of the functionality of an application by implementing business rules which add (within limits) to the semantics of POSTs and DELETEs.
Business rules cannot change the fundamental semantics of these verbs. A successful POST to a Node Group or Edge Group must still add a new Node or Edge. A successful POST to a Node or Edge must still make the specified modifications to the Node or Edge, and a successful DELETE must still result in the specified deletion.
In particular, POST to a Node or Edge must remain idempotent. POSTing twice to a Node or Edge must have exactly the same effect as POSTing once.
Business rules, however, can reject requests which violate a desired constraint. We might want to disallow deletion of students prior to their 21st birthday.
Business rules can also limit operations to specific users or classes of user. Our school system might have an administrator class who are responsible for placing students in classes. An attempt to add a Student Edge to a class would be rejected if the client making the request was not identified as an administrator.
Business rules also have broad authority to make additional changes to the back end data structures based on a POST or DELETE. We could add a property to Student showing the number of classes each student is enrolled in, and then when the client POSTs to the schedule Edge Group to add a new Course, increment this count in the Student Node.
As I mentioned earlier, the client is not allowed to construct URLs, but is required to retrieve them from the server. It is, however, allowed to append query parameters. These must have no effect on the query other than limiting the set of records returned.
Here are some examples.
GET /student?name=piers*
GET /student/student-10706/schedule?tardies=0
GET /student?schedule.tardies=gt.0
In the first two cases the query is based on a property of the Node or Edge. The first is intended to retrieve all students whose name begins with “piers”, the second to get all courses where the given student is currently enrolled and has no tardies.
The third example shows a query that would be achieved with a join in SQL. It is imagined to retrieve all students which have been late for at least one class.
Note that the HTTP query syntax doesn’t really support the kind of database queries we want to perform very well, and because of that we have not yet settled on standards for specifying queries (and different projects have come up with different solutions). We are still striking out into new territory, but remain clear that we want to be working toward a company wide solution in the long term.
Some Node Groups contain a lot of Nodes. At IMVU we have a Node Group for the tens of millions of products in our catalog. We don’t currently support querying our product Node Group, but if we did, we would have to get a response back something like this:
{ …
{
"nodes": [
"/product/product-10057",
"/product/product-10092",
...
"/product/product-11033",
],
"next": "/product?offset=50",
}
}
The list of Nodes includes only the first fifty, but provides us with a URL – with a built-in query parameter – which allows us to retrieve another group of fifty.
There are a number of services which do paging like this, but note that offsets don’t work very well for paging when Nodes are often being added and deleted, since the offsets associated with specific Nodes can change. Paging is another area in which our standards are still under development.
Finally, in order to allow clients to cache the responses they receive we provide a way for the service to let the client know when cached URL responses are no longer valid.
This involves the use of IMQ, IMVU’s proprietary system for efficiently pushing data to clients in real time. In our case, the data is simply a notification that an earlier response to a particular URL is no longer valid. We’ll go into detail on IMQ and how it works in a future post.
Most endpoints do not provide invalidation. IMVU product information, for example, doesn’t change often enough to make the overhead associated with invalidation worthwhile.
When invalidation is available, the response to an endpoint will include a member called “updates”, which provides the information necessary to subscribe to the appropriate IMQ queue. Here is a response to a GET of a particular enrollment Edge
(/student/student-513312/schedule/01):
{
{
"data": {
"tardies": 1,
},
"relations": {
"ref": "/course/course-1035",
}
"updates": "imq://inv.student.student-513312"
}
}
Invalidations for different endpoints come in on different queues, and it is the server’s prerogative to choose the queue for each endpoint.
Currently, for the endpoints which support invalidation, we have one queue per Node. Invalidations for the Node come in on this queue, but the same queue also provides invalidations for the Node’s Edge Groups and Edges. This design allows us to achieve a balance between the number of queues we create and the number of subscribers to each queue.
In the example above, only clients that have an active interest in Student 513312 will be subscribed to this queue. With this mechanism, if someone POSTs a change to the number of tardies, every client which has this record cached will receive a notification. If the number of tardies is displayed on the screen, it can be updated immediately.
Note that under this scheme, there can be no queue associated with a Node Group. Such a queue would be used to notify all clients that, for example, a new Student Node had been added. To be useful, however, every client application would need to subscribe to the queue, and IMQ is not built to support such a large number of subscribers. There are solutions to this problem, but for the moment we do not support invalidation for Node Groups.
The discipline of REST and the specific uniform contract IMVU has adopted give us the power and flexibility to quickly create, enhance and share back end services. The principles behind REST (and especially the principles of uniform contract, HATEAOS and separation of concerns) provide us with a solid framework as we continue to complete and codify our standards.
We’ll keep you up to date as things develop.